這邊跟大家介紹一套做 DB migration 的好東西 pt-online-schema-change,這是可以讓 DBA 省時省心力的工具,他可以用簡單的指令讓修改資料表結構時不鎖表(可寫入)與接近零 downtime 的好物。

興趣使然的軟體工程師,擅長 Exception。

上次 [C#] SQL 資料庫 Connection Pool 連線池觀念釐清 有提到可以開啟 Connection Pool 來減少開啟連線的效能耗損,但最近發現有 Stored Procedure 執行後沒有手動 Drop Temp Table,而 .NET 又將連線丟回 Pool 裡面造成 Temp Table 沒有被正常釋放的問題,下面來測試看看是不是真的會有這種情況發生。
目前工作 Database 方面主要都在使用 SQL Server,寫了近兩年的 Stored Procedure 也遇到了許多的問題,在這裡簡單筆記一下。
SET NOCOUNT ON
DECLARE
@RowNum INT,
@RowCount INT,
@Temp_Id INT
SELECT
ROW_NUMBER() OVER(ORDER BY [Id]) AS RowNum,
[Id],
[Name]
INTO
#Temp
FROM
[exfast].[dbo].[TableA] WITH(NOLOCK)
SELECT
@RowNum = 1,
@RowCount = (SELECT SUM(1) FROM #Temp)
WHILE(@RowNum <= @RowCount)
BEGIN
SELECT
@Temp_Id = [Id]
FROM
#Temp
WHERE
RowNum = @RowNum
UPDATE
[exfast].[dbo].[TableA]
SET
[Name] = 'dddd'
WHERE
[Id] = @Temp_Id
SET @RowNum = @RowNum + 1
END
DROP TABLE #Temp
DECLARE @TempA TABLE
(
[INSERTED_Id] INT,
[INSERTED_Name] NVARCHAR(32),
[DELETED_Id] INT,
[DELETED_Name] NVARCHAR(32)
)
UPDATE
[exfast.Helper].[dbo].[TableA]
SET
[Name] = 'qqqq'
OUTPUT
INSERTED.[Id],
INSERTED.[Name],
DELETED.[Id],
DELETED.[Name]
INTO
@TempA
SELECT * FROM @TempA
-- 故意指定隔離層級模擬撞車的情況
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE
BEGIN TRAN
SELECT * FROM [exfast.Helper].[dbo].[TableA]
WAITFOR DELAY '00:00:10'
UPDATE
[exfast.Helper].[dbo].[TableA]
SET
[Name] = 'cccc'
WHERE
[Id] = 2
ROLLBACK
環境:Window 7
docker volume create vol-mssql
docker run \ --restart=always \ --name mssql \ --mount "source=vol-mssql,target=/var/opt/mssql" \ -e "ACCEPT_EULA=Y" \ -e "SA_PASSWORD=1OCHWiY9O#RF" \ -e "MSSQL_PID=Express" \ -e "MSSQL_COLLATION=Chinese_Taiwan_Stroke_CI_AS" \ -p 1433:1433 \ -d microsoft/mssql-server-linux:latest
docker exec -ti mssql bash apt-get update apt-get install tzdata -y dpkg-reconfigure tzdata
參考資料:
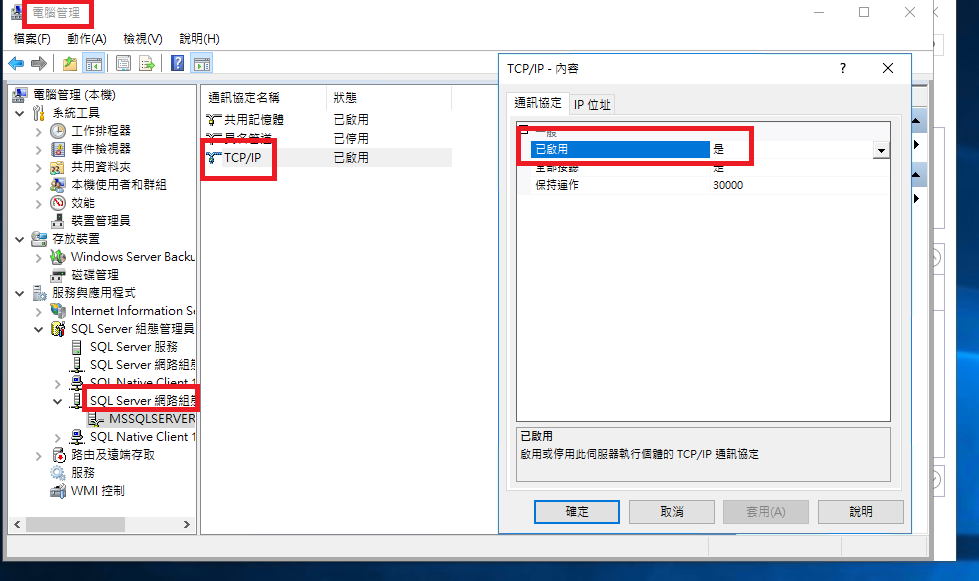
這樣就可以用預設 port 1433 連線囉

這題非常有趣,題目要求寫一預存程式輸入N並取出排名第N名的薪水為多少,這題與178. Rank Scores差不多,所以可以直接套用。
Write a SQL query to get the nth highest salary from the
Employeetable.+----+--------+ | Id | Salary | +----+--------+ | 1 | 100 | | 2 | 200 | | 3 | 300 | +----+--------+For example, given the above Employee table, the nth highest salary where n = 2 is
200. If there is no nth highest salary, then the query should returnnull.
178. Rank Scores的解法直接套上去取N
CREATE FUNCTION getNthHighestSalary(N INT) RETURNS INT
BEGIN
RETURN (
# Write your MySQL query statement below.
SELECT a.Salary
FROM (SELECT (@row_number:=@row_number + 1) AS Rank, z.Salary
FROM ( SELECT x.*
FROM Employee AS x
GROUP BY x.Salary
ORDER BY x.Salary DESC) AS z
JOIN (SELECT @row_number := 0) AS y) AS a
WHERE a.Rank = N
);
END
LIMIT來獲取Nth(因為LIMIT是從0開始所以N必須先減一),非常易懂的解法。
CREATE FUNCTION getNthHighestSalary(N INT) RETURNS INT
BEGIN
DECLARE M INT;
SET M = N - 1;
RETURN (
# Write your MySQL query statement below.
SELECT Salary
FROM Employee
GROUP BY Salary
ORDER BY Salary DESC
LIMIT M, 1
);
END
參考:

題目要求找出每個部門薪水最高的員工,若同部門最高薪水有複數則一起顯示,這題我在JOIN部門清單的時候先去把各部門最高薪資數字先撈了出來,這樣在關聯兩張表的時候就可以直接搜尋員工薪水是否等於最高薪資。
The
Employeetable holds all employees. Every employee has an Id, a salary, and there is also a column for the department Id.+----+-------+--------+--------------+ | Id | Name | Salary | DepartmentId | +----+-------+--------+--------------+ | 1 | Joe | 70000 | 1 | | 2 | Henry | 80000 | 2 | | 3 | Sam | 60000 | 2 | | 4 | Max | 90000 | 1 | +----+-------+--------+--------------+The
Departmenttable holds all departments of the company.+----+----------+ | Id | Name | +----+----------+ | 1 | IT | | 2 | Sales | +----+----------+Write a SQL query to find employees who have the highest salary in each of the departments. For the above tables, Max has the highest salary in the IT department and Henry has the highest salary in the Sales department.
+------------+----------+--------+ | Department | Employee | Salary | +------------+----------+--------+ | IT | Max | 90000 | | Sales | Henry | 80000 | +------------+----------+--------+
JOIN部門清單的時候先去把各部門最高薪資數字先撈了出來
# Write your MySQL query statement below
SELECT b.Name AS Department,
a.Name AS Employee,
a.Salary AS Salary
FROM Employee AS a
JOIN ( SELECT z.*, (SELECT MAX(y.Salary)
FROM Employee AS y
WHERE z.Id = y.DepartmentId
LIMIT 0, 1) AS MaxSalary
FROM Department AS z) AS b
ON a.DepartmentId = b.Id AND a.Salary = b.MaxSalary
# Write your MySQL query statement below
SELECT b.Name AS Department,
a.Name AS Employee,
a.Salary AS Salary
FROM Employee AS a
JOIN Department AS b
ON a.DepartmentId = b.Id
WHERE ( SELECT COUNT(DISTINCT(z.Salary))
FROM Employee AS z
WHERE a.DepartmentId = z.DepartmentId
AND a.Salary < z.Salary) = 0

題目要求找出成績排名,如果分數相同的話則相同名次,MySQL不像MSSQL有ROW_NUMBER()可以用,只好用個變數來存了。
Write a SQL query to rank scores. If there is a tie between two scores, both should have the same ranking. Note that after a tie, the next ranking number should be the next consecutive integer value. In other words, there should be no “holes” between ranks.
+----+-------+ | Id | Score | +----+-------+ | 1 | 3.50 | | 2 | 3.65 | | 3 | 4.00 | | 4 | 3.85 | | 5 | 4.00 | | 6 | 3.65 | +----+-------+For example, given the above
Scorestable, your query should generate the following report (order by highest score):+-------+------+ | Score | Rank | +-------+------+ | 4.00 | 1 | | 4.00 | 1 | | 3.85 | 2 | | 3.65 | 3 | | 3.65 | 3 | | 3.50 | 4 | +-------+------+
# Write your MySQL query statement below
SELECT a.Score, b.Rank
FROM Scores AS a
JOIN (SELECT (@row_number:=@row_number + 1) AS Rank, z.Score
FROM (SELECT x.*
FROM Scores AS x
GROUP BY x.Score
ORDER BY x.Score DESC) AS z
JOIN (SELECT @row_number := 0) AS y) AS b
ON a.Score = b.Score
ORDER BY `b`.`Score` DESC